The ubiquitous rise of Large Language Models (LLMs) has amplified the demand for efficient structured content generation, from code to structured data formats like JSON. While existing methods for generating outputs conforming to specific grammars (like LR(1) grammars) have enabled impressive capabilities, they often introduce significant runtime overhead, particularly under large inference batching scenarios. This post introduces Pre$^3$, a novel approach that leverages Deterministic Pushdown Automata (DPDA) to revolutionize the speed and efficiency of structured LLM generation.
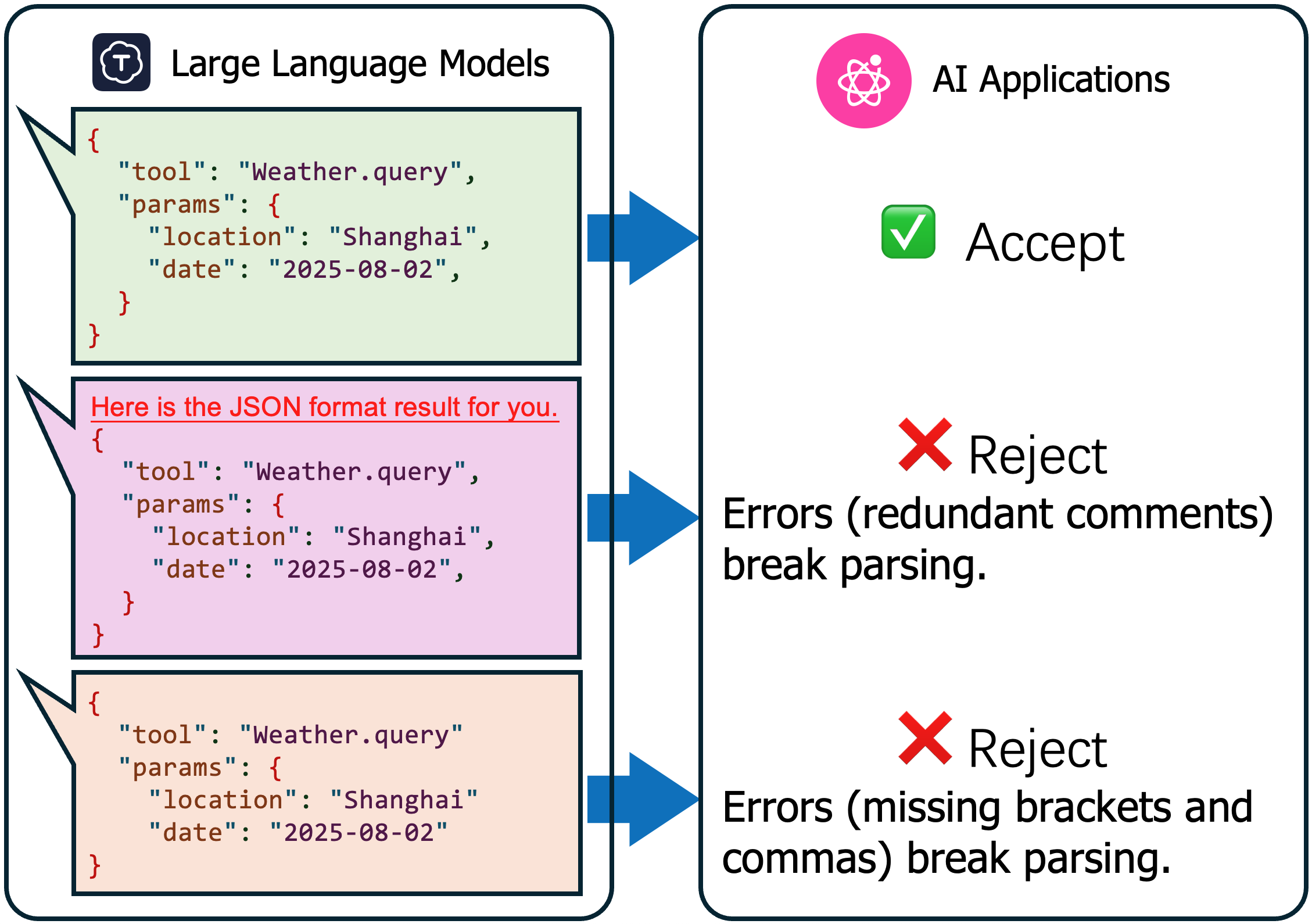
Structured generation means LLM produces formatted data (JSON, SQL, code) instead of free text, enforce strict syntax rules for machine-readable output.
The Bottleneck of Current Structured LLM Generation
Current state-of-the-art methods for constrained LLM decoding typically involve parsing LR(1) grammars into Pushdown Automata (PDAs). While effective, this process incurs substantial runtime execution overhead for context-dependent token processing, especially inefficient under large inference batches. This sequential and context-aware validation becomes a significant bottleneck, akin to navigating a complex maze one step at a time, checking every turn.
Per token latency comparison (in milliseconds) across different batch sizes.

Pre$^3$: A Paradigm Shift with Deterministic Pushdown Automata
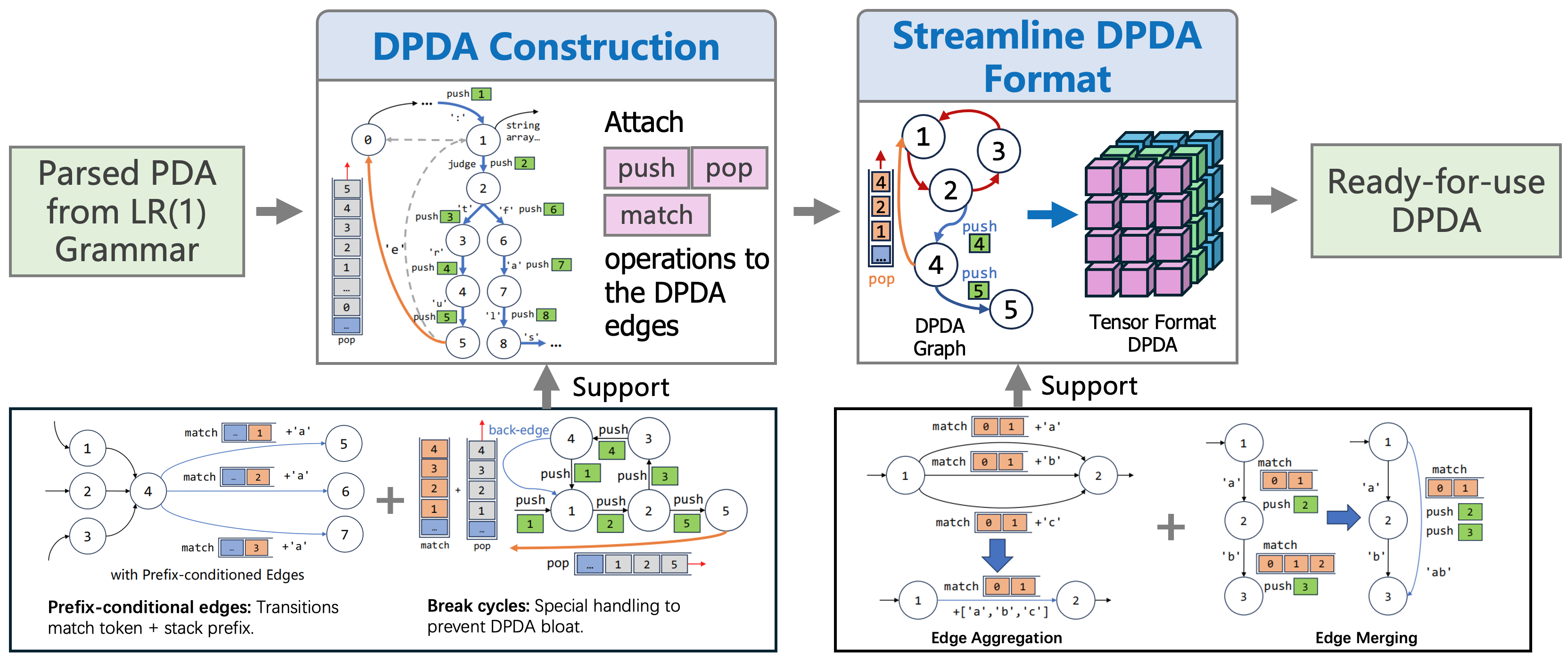
Pre$^3$ addresses these efficiency limitations by exploiting the power of Deterministic Pushdown Automata (DPDA). The core innovation lies in transforming the traditional, often non-deterministic, PDA-based decoding into a highly optimized, deterministic process. The workflow of Pre$^3$ is illustrated in the figure below.
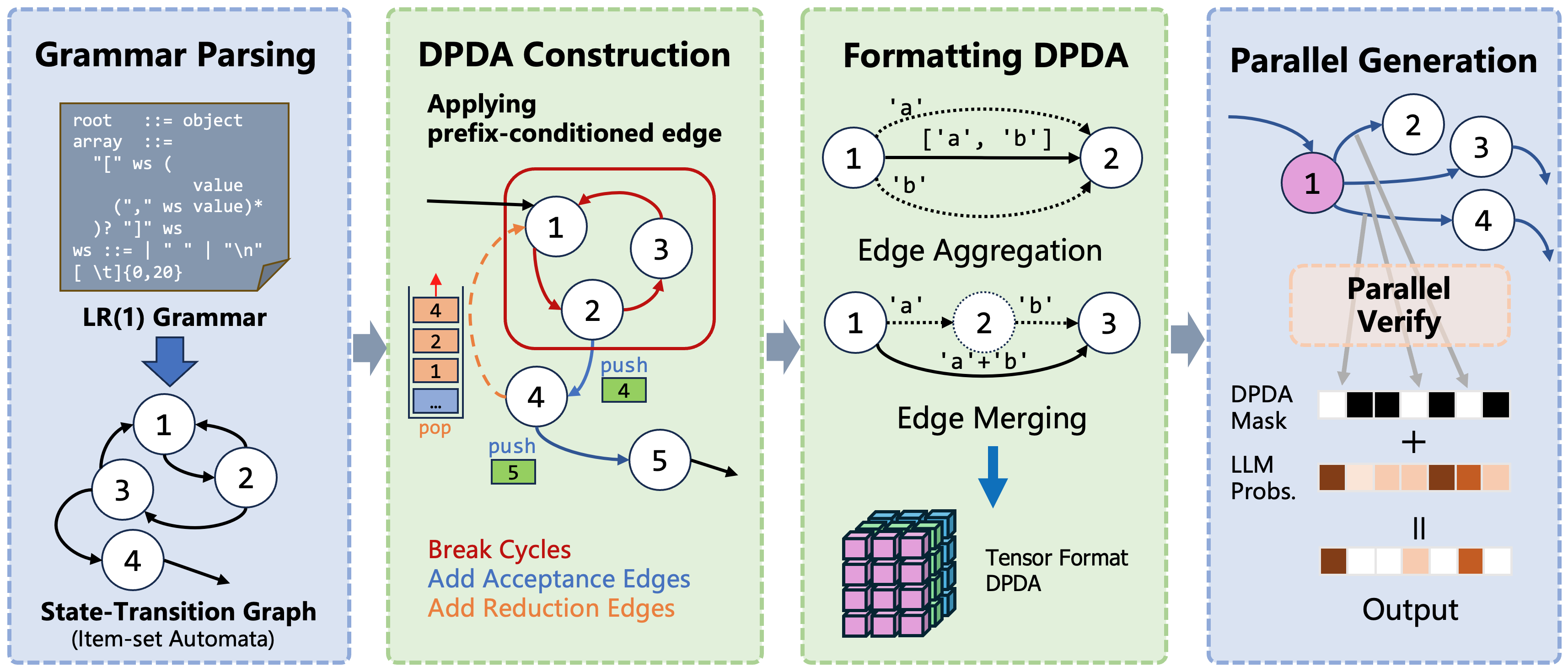
Pre³ Workflow outlines our approach to convert LR(1) grammars into DPDAs by precomputing all transitions, enabling efficient table lookup over runtime exploration.
1. Precomputation of Prefix-Conditioned Edges
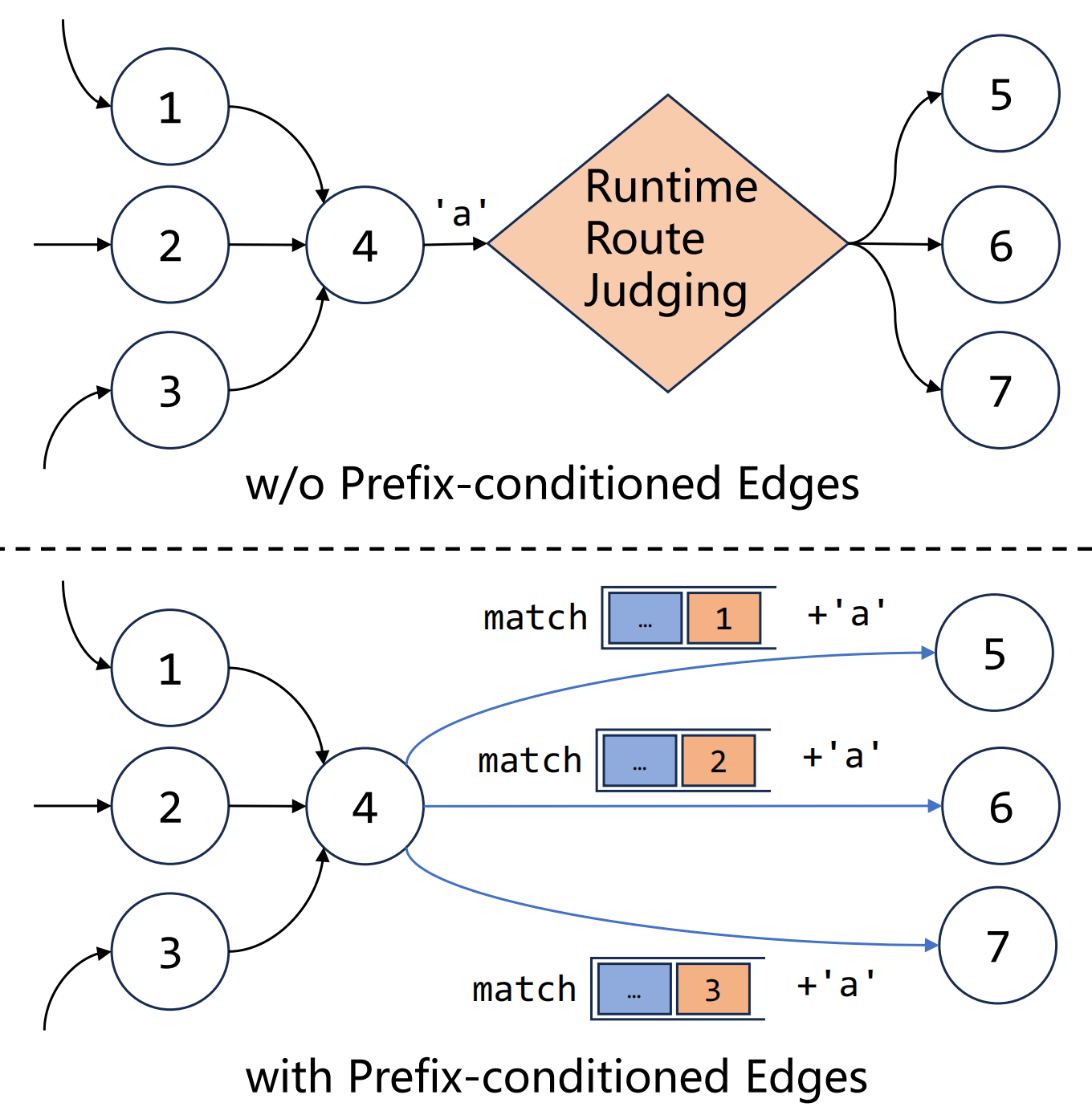
Pre-computed transitions using stack prefixes and input symbols eliminate runtime ambiguity in parsing.
Generated with two types of DPDA edges (acceptance edge and reduction edge) through graph traversal.
One of Pre$^3$’s key strengths is its preprocessing stage, where it precomputes “prefix-conditioned edges”. This anticipatory analysis offers several advantages:
- Ahead-of-Time Analysis: Unlike reactive validation, Pre$^3$ proactively analyzes all possible grammar transitions before the LLM even begins generating. This is analogous to pre-planning all possible routes and turns on a journey before setting off.
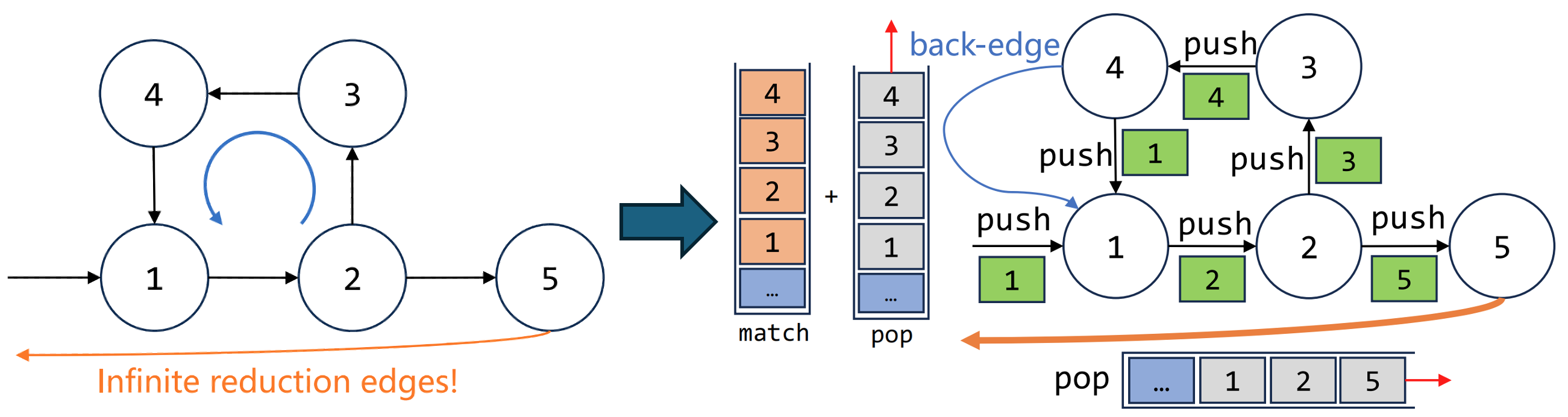
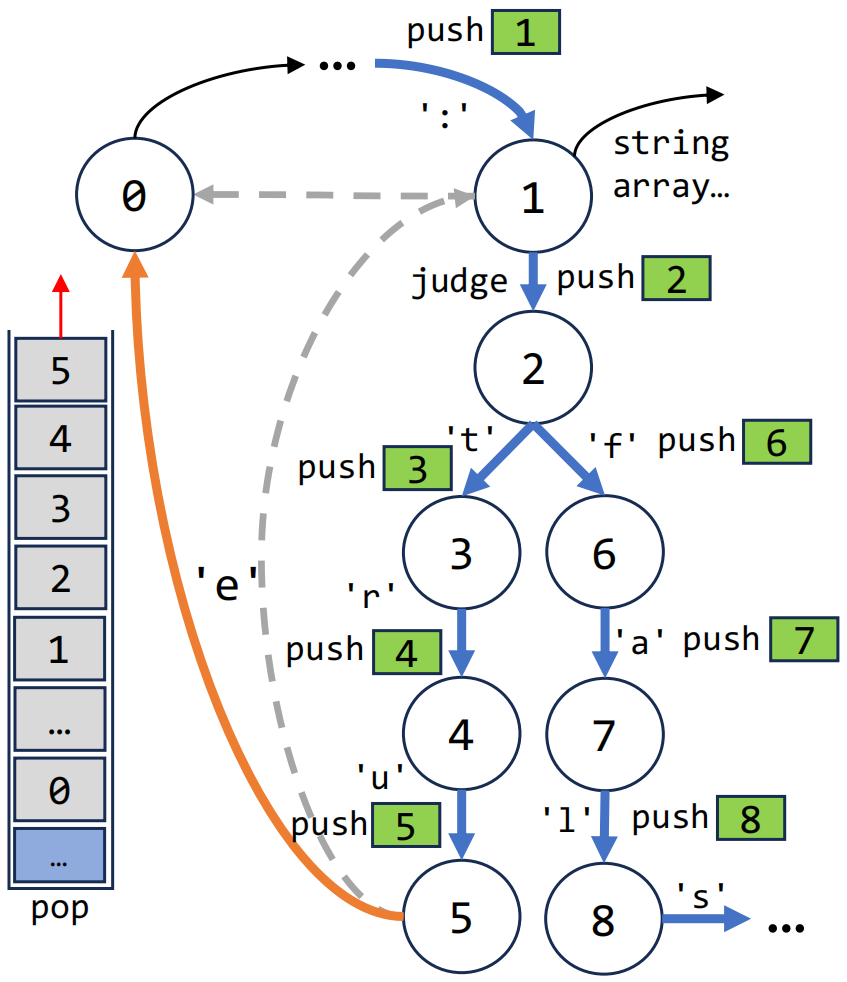
Pre³ uses a back-edge to break cycles and only one reduction edge is required.
-
Break Cycles: Raw DPDAs will repeatedly reduce the same sequence of symbols and create an infinite number of reduction edges. By adding the back-edge using the match and pop operations only one reduction edge is required.
- Reduce-reduce or shift-reduce conflicts (collectively known as cycle issues) are a common phenomenon when parsing LR(1) grammars. A concrete example of this phenomenon is depicted in the figure below.
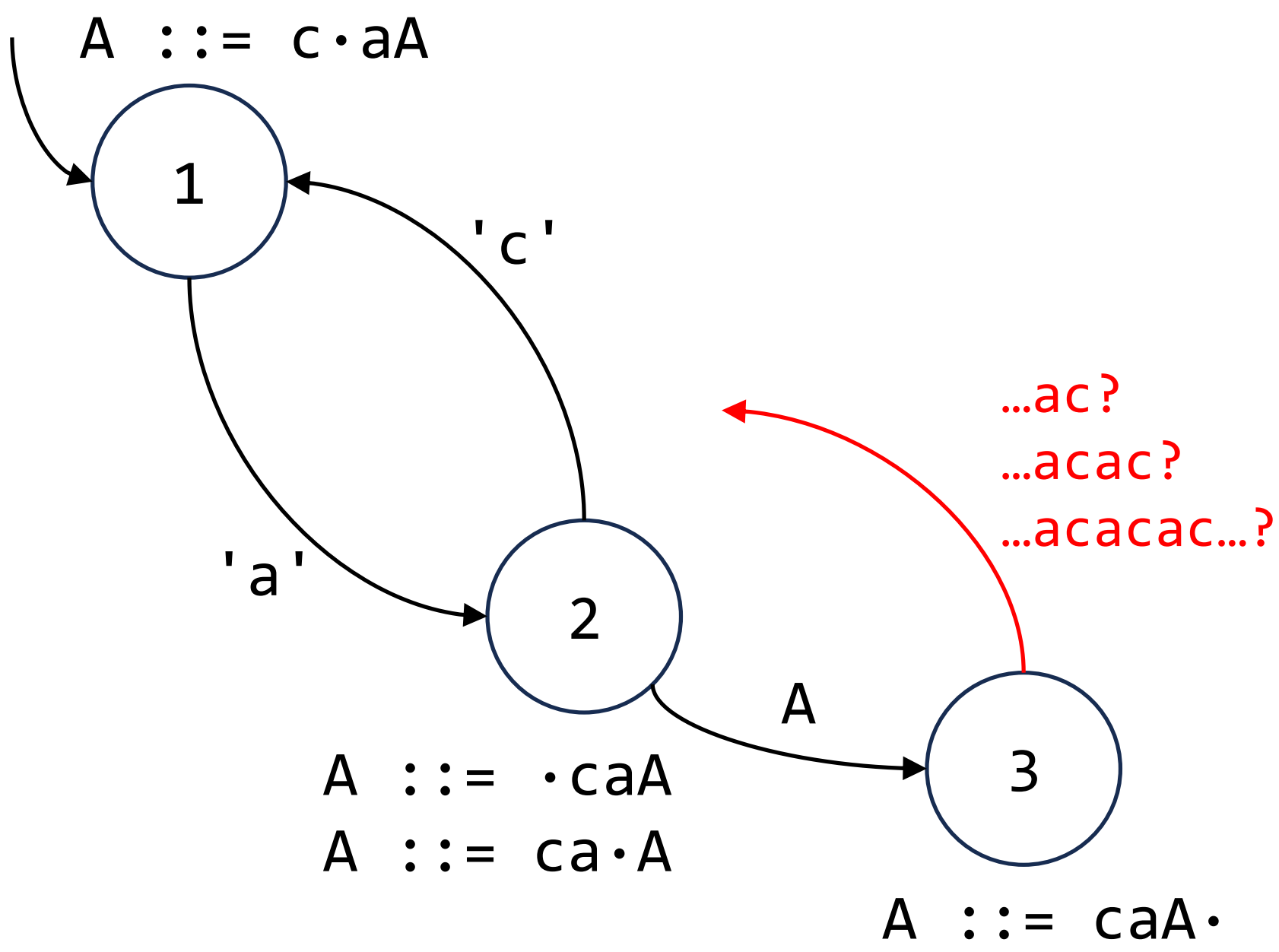
An example about cycle issue when a LR(1) item-set automata recieve repeated "ac".
- Our solution can be illustrated with an example in the figure above: Pushdown automaton with an infinite cycle between State 1, 2, 3, 4, leading to an infinite number of possible paths and indeterminable transition paths when adding reduction edges at State 5; The back-edge from State 4 to State 1 is modified to check for complete cycle traversal information (e.g., [1, 2, 3, 4]) in the stack. If detected, it pops the redundant state (e.g., [1, 2, 3, 4]), ensuring reduction edges at State 5 only need to account for traversals without cycles.
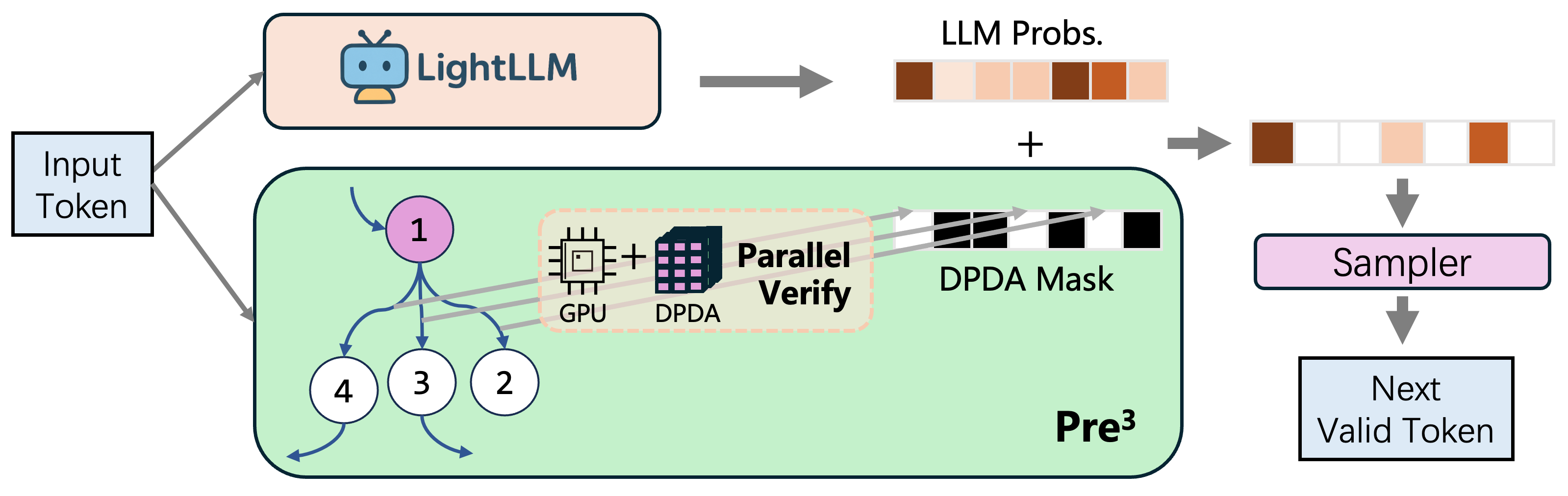
Enabling parallel transition processing with LightLLM.
-
Enabling Parallel Transition Processing: The deterministic nature of DPDAs, combined with precomputation, allows for parallel processing of transitions. In a non-deterministic PDA, multiple choices might exist for a given state, input, and stack top, necessitating sequential exploration. DPDA’s determinism, however, ensures a unique next step, paving the way for parallel computations.
The DPDA, fundamental to Pre$^3$, imposes strict constraints:
- For any state $q$, stack symbol $A$, and input symbol $a \in \Sigma$, there is at most one pair $(p, \gamma) \in \delta(q, a, A)$.
- If an $\epsilon$-move is possible from $(q, A)$, then no non-$\epsilon$-move can be made from the same $(q, A)$.
These conditions guarantee that at most one transition is available in any situation, making the automaton deterministic. This determinism is precisely what empowers Pre$^3$ to perform effective precomputation and parallel processing.
Pre³ converts LR(1) grammar into a DPDA by precomputing transitions, replacing runtime exploration with efficient table lookup.
2. Streamlining Automata Structure
Beyond the precomputation of edges, Pre$^3$ further optimizes the underlying automaton structure itself to maximize efficiency during inference. This involves two key enhancements:
-
Minimizing Redundant States: Traditional PDA constructions can often result in a large number of states, some of which may be redundant or unreachable, leading to unnecessary computational overhead. Pre$^3$ incorporates techniques to simplify the DPDA by identifying and merging equivalent states or removing inaccessible ones. This reduction in complexity means fewer lookups and comparisons during the decoding process.
-
Optimized Transition Processing: The way state transitions are stored and accessed is critical for performance. Pre$^3$ employs an optimized representation for the DPDA’s transitions, ensuring that the LLM can parallel determine the next valid token based on its current state and the grammar constraints. The goal is to ensure that the grammar-based constraints are applied with minimal computational footprint, allowing the LLM’s core generation process to run as unhindered as possible.
Experiment Results
Pre$^3$ was evaluated against several state-of-the-art and popular structure generation engines, including XGrammar, Outlines, and llama.cpp. Experiments were conducted on a server equipped with an Intel(R) Xeon(R) Gold 6448Y CPU and 8 NVIDIA H800 GPUs. The datasets used included JSON-mode-eval and additional private data.
Per-step Decoding Efficiency
To assess the improvement in decoding efficiency, the per-step decoding overhead was measured, defined as the difference between grammar-based decoding time and original decoding time. Experiments were conducted using Meta-Llama-3-8B and Meta-Llama-2-70B models with JSON and chain-of-thought grammars.
- Key Finding: Pre$^3$ consistently introduces less overhead than previous SOTA systems, outperforming Outlines and llama.cpp, and maintaining a consistent advantage over XGrammar. For instance, XGrammar showed up to 37.5% higher latency (147.64 ms vs. 92.23 ms) at batch size 512 compared to unconstrained decoding when evaluating on Meta-Llama-3-8B. This performance gap widened with increasing batch sizes.
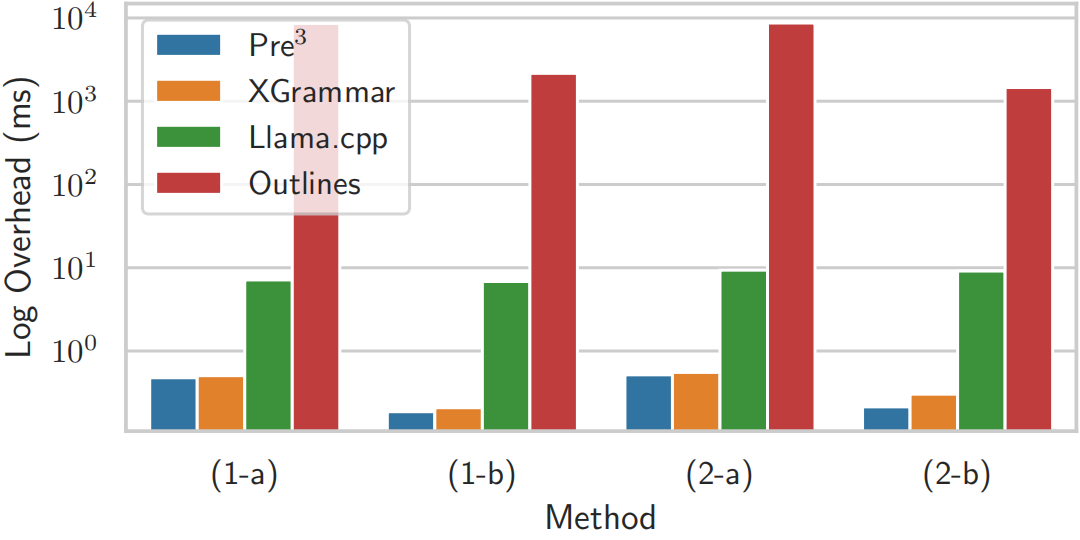
Evaluation on per-step decoding efficiency.
Large Batch Inference Efficiency and Real-world Deployment Throughput
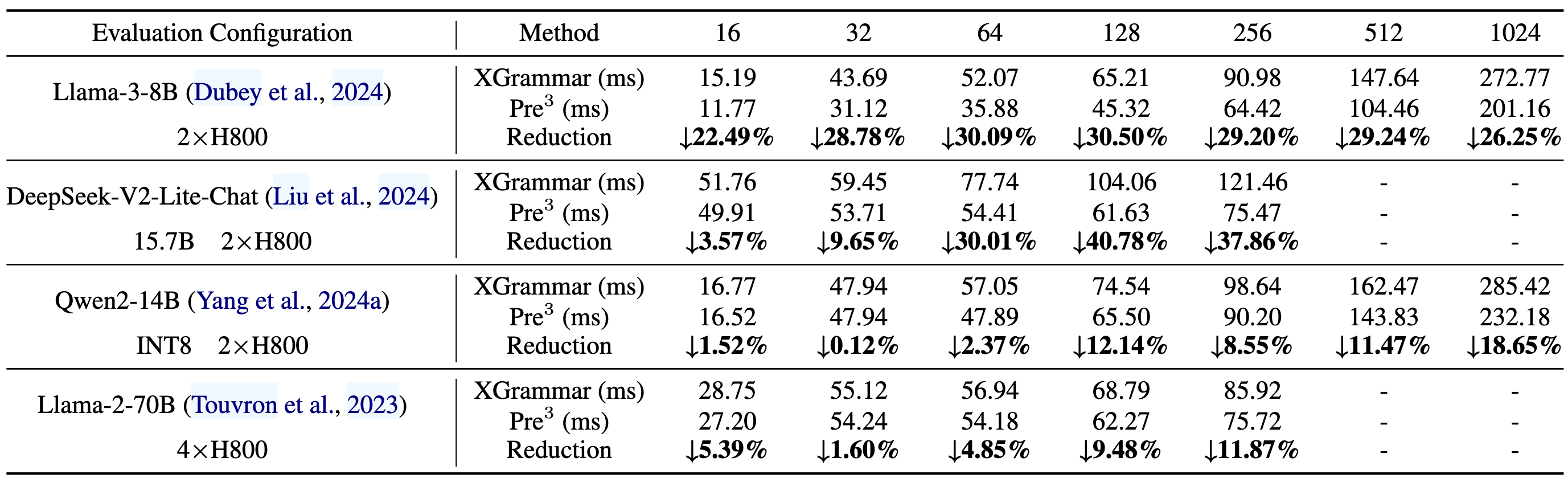
In real-world serving scenarios, efficient large-batch processing is crucial. Pre$^3$ was benchmarked against XGrammar using the complex JSON grammar, with experiments conducted on Llama3-8B, Deepseek-V2 (15.7B), and Llama2-70B models, with batch sizes up to 1024.
To assess real-world performance, the throughput of Pre$^3$ and XGrammar was compared under varying system concurrency levels using Meta-Llama-3-8B and Meta-Llama-2-70B
- Key Finding: Pre$^3$ consistently outperformed XGrammar in all scenarios, achieving latency reductions of up to 30%. The advantage was more pronounced at larger batch sizes, demonstrating Pre$^3$’s scalability. Pre$^3$ also demonstrated an improvement over XGrammar in real-world serving, achieving up to 20% higher throughput at higher concurrency levels.
Evaluate batch decoding efficiency.
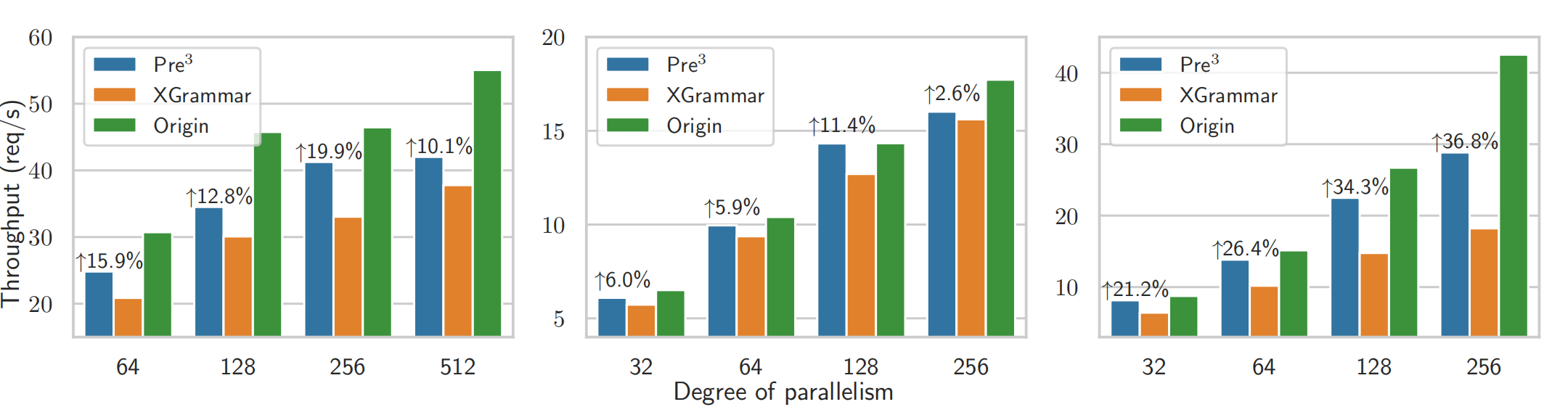
Benchmark under production-like serving conditions.
Conclusion
Pre$^3$ represents a significant leap forward in optimizing structured LLM generation. By cleverly leveraging the properties of Deterministic Pushdown Automata and employing an effective precomputation strategy, it resolves the long-standing efficiency bottlenecks of context-dependent token processing. This innovation opens up new avenues for deploying LLMs in high-throughput, precision-critical applications, promising a future where structured content generation is not only accurate but also remarkably fast and efficient.