We are delighted to announce the release of LightLLM v1.1.0! This version introduces a CPU-GPU unified folding architecture, which significantly reduces system-level CPU overhead for more efficient execution. We’ve also performed deep optimizations for DeepSeek and Qwen3-MoE, including integration of DeepEP/DeepGEMM, fused MoE Triton optimizations, a balanced DP request scheduler, support for MTP and autotuner for triton kernels. In addition, we’ve introduced a novel constrained decoding solution, recognized with the ACL Outstanding Award, enabling high-performance structured generation. Finally, we further improve the performance of multimodal inference.
CPU-GPU Unified Folding Architecture
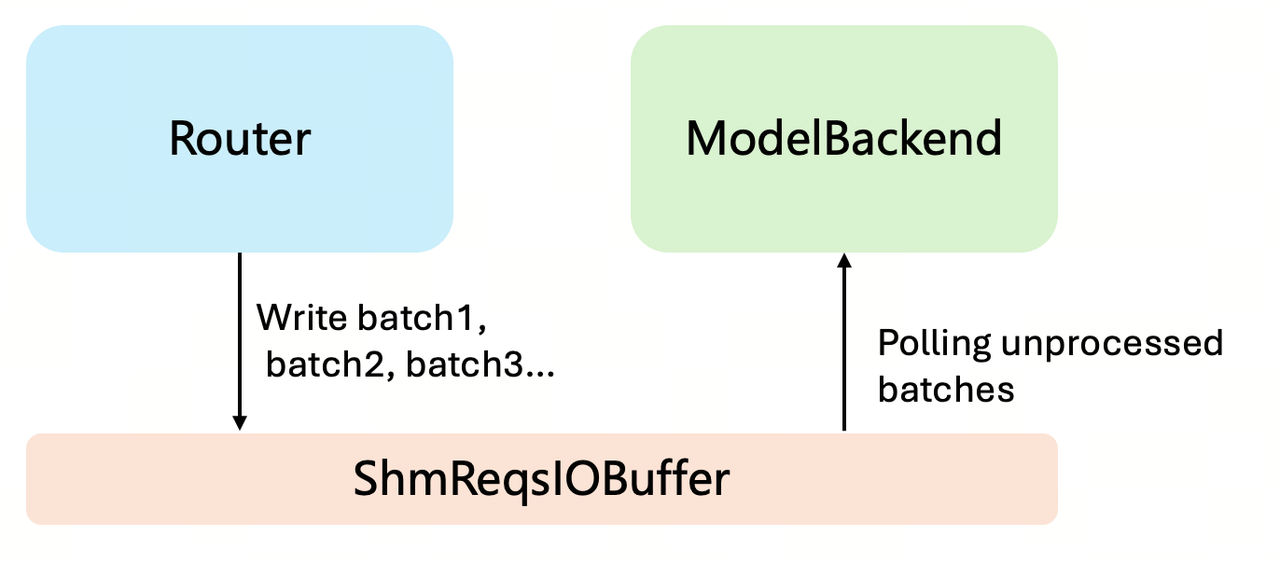
In the previous version of LightLLM, there was still a considerable CPU overhead. To resolve this, we restructured both the interaction between the Router and model inference, as well as the inference workflow. Specifically, we inherited the inter-process shared ShmReq from the previous version and further decoupled the Router’s request scheduling and model inference. As shown in the figure below, the Router is only responsible for scheduling requests at fixed intervals and placing the scheduled batches into the ShmReqsIOBuffer.
And the ModelBackend continuously polls the ShmReqsIOBuffer, and as soon as a batch is available, it is processed immediately. It achieves complete asynchronization between the Router and the inference process.
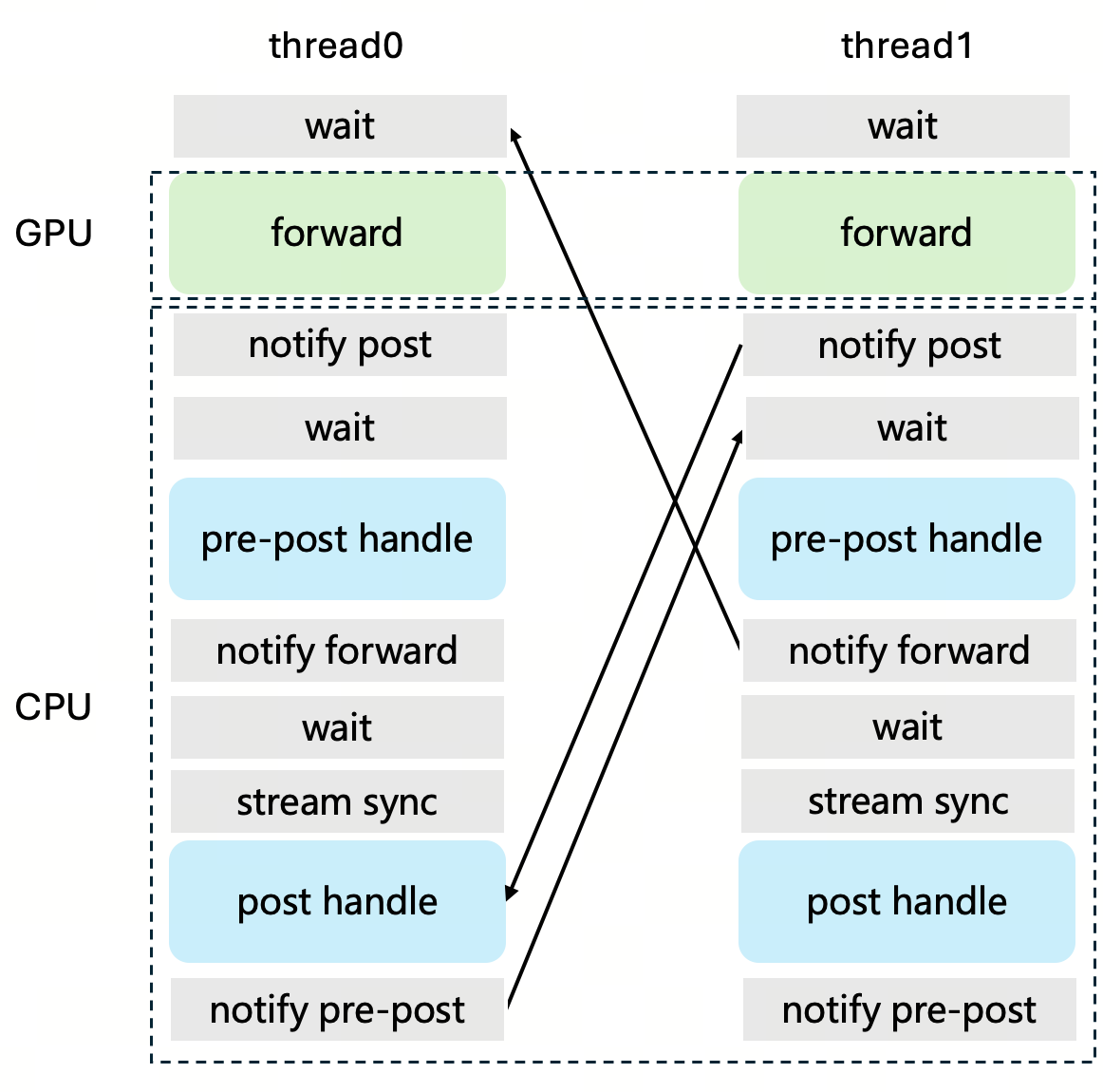
Moreover, to eliminate CPU overhead in the ModelBackend, we introduced two cooperative inference threads, which not only effectively folds the pre- and post-processing overhead of inference, but also preserved high code readability. As shown in the figure below, we achieve GPU–CPU overlap through continuous switching between two inference threads. If thread 1 has already launched the GPU forward, it will then notify thread 0 to finish the post-handling of the previous batch 0, followed by the pre-post-handling of the current batch.
MOE Optimization
LightLLM 1.1.0 also introduces optimizations for MoE (Mixture of Experts) models, such as Qwen3-235B-MOE and DeepSeek-R1.
Tensor Parallel: For tensor parallelism, we performed fine-grained optimizations on our Triton MoE kernels. We introduced three MoE align Triton kernels and optimized the L2 cache usage of the group GEMM Triton kernel. Moreover, we added the transpose option into the configuration search space in order to achieve better performance. A performance comparison between our fused MoE implementation and that of sglang/vLLM is shown below.
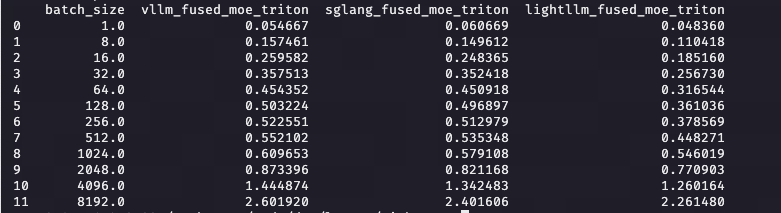
DeepSeek-671B/tp8/fp8/H200
Data Parallel: For data parallelism, we integrated DeepSeek’s open-source components DeepGEMM and DeepEP, and implemented micro-batch compute–communication folding. To improve expert load balancing, we also introduced a dynamically adaptive redundant expert strategy. For data-parallel request scheduling, benefited from our complete decoupling between scheduler and ModelBackend, we can more easily implement diverse scheduling policies. And we provide a greedy scheduling strategy to maximize the likelihood that every DP rank always has requests to process.
MTP: LightLLM 1.1.0 also adds support for MTP and implements draft token verification directly on the GPU using Triton kernels, ensuring that CPU–GPU folding continues to work effectively.
Autotuner for triton kernels
To fully optimize the performance of Triton kernels, we designed an autotuner.
You can configure its behavior by setting the environment variable LIGHTLLM_TRITON_AUTOTUNE_LEVEL when starting the service:
- 0: Use cached configurations from
/lightllm/common/triton_utils/autotune_kernel_configs - 1: Autotune only if no cached configuration exists (recommended)
- 2: Always autotune and overwrite cached configurations
- 3: Disable autotune and use configurations from
lightllm/common/all_kernel_configs
(these are manually tuned configurations, generated using scripts intest/kernels)
Pre³ for Structured LLM Generation
LightLLM introduces Pre³, a novel approach that leverages Deterministic Pushdown Automata (DPDA) to dramatically enhance the speed and efficiency of structured LLM generation. For more details, see the blog post: https://www.light-ai.top/lightllm-blog/2025/06/15/pre3.html.
Performance
We validated both tensor parallel (TP) and data parallel (DP) deployment modes of the DeepSeek-671B model on 8×H200-80G GPUs. We conducted three groups of experiments: input–output lengths of 1k–1k, 4k–1k, and 8k–1k. Each group used 200 requests at a rate of 100 QPS. The results, shown below, demonstrate that LightLLM consistently outperforms the sglang==0.5.2rc0 and vllm==0.10.1.1.
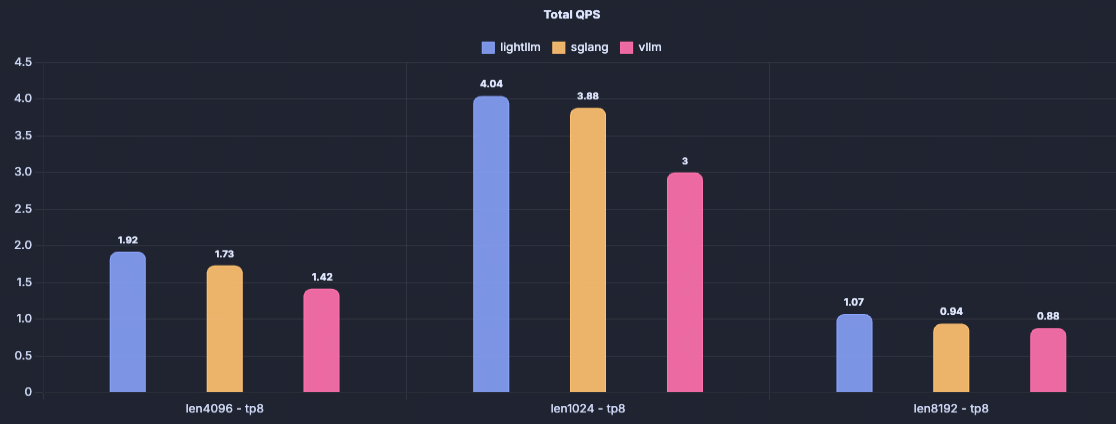
DeepSeek-671B/tp8/fp8/H200
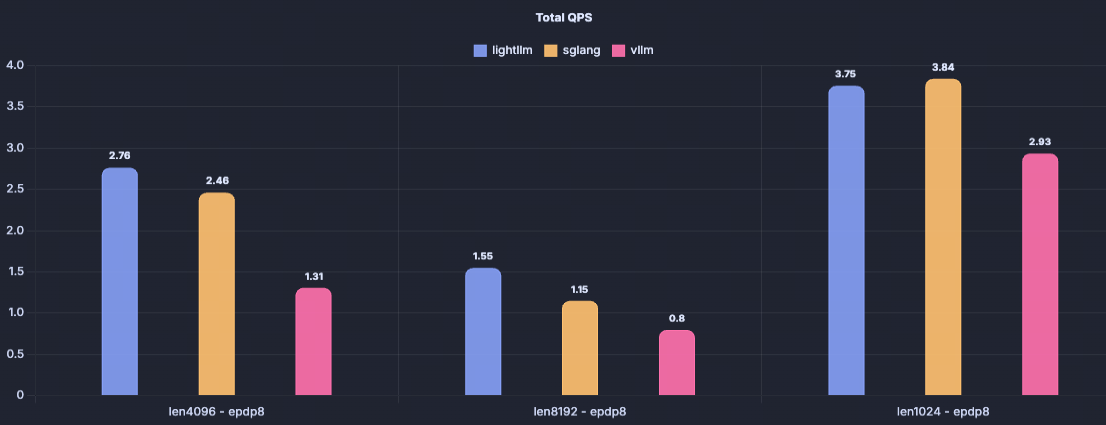
DeepSeek-671B/dp8ep8/fp8/H200
Thanks to our fully folded CPU–GPU architecture, multimodal image preprocessing can also be effectively folded, leading to improved multimodal inference performance. Below is a performance comparison of LightLLM and other frameworks on Qwen2.5-VL-72B with a single H200 GPU.
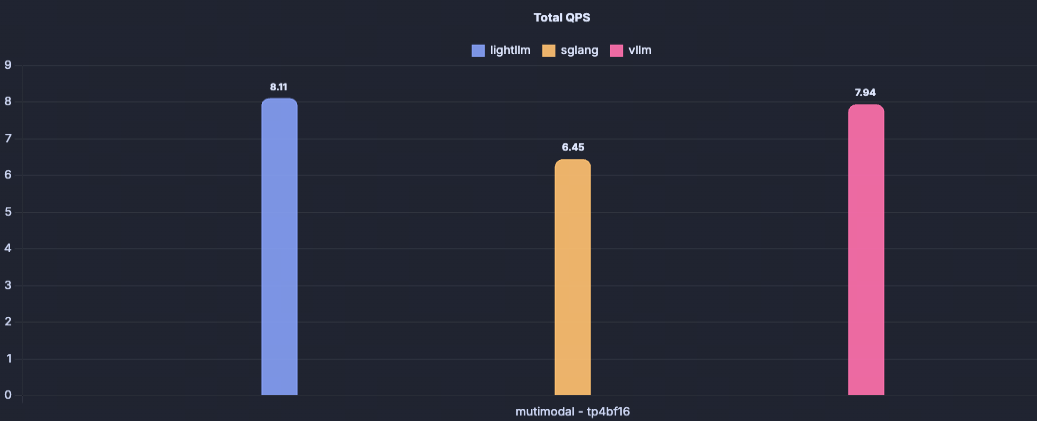
Qwen2.5-VL-72B/tp4/bf16/H200
Acknowledgment
We learned a lot from the following projects when developing LightLLM, including vLLM, sglang, and OpenAI Triton. We also warmly welcome the open-source community to help improve LightLLM.