Custom MTP Operator
Due to our unique inference pattern, during the decode phase, adjacent sequences in the batch share the same KV cache, with the only difference being that sequence lengths increment progressively.
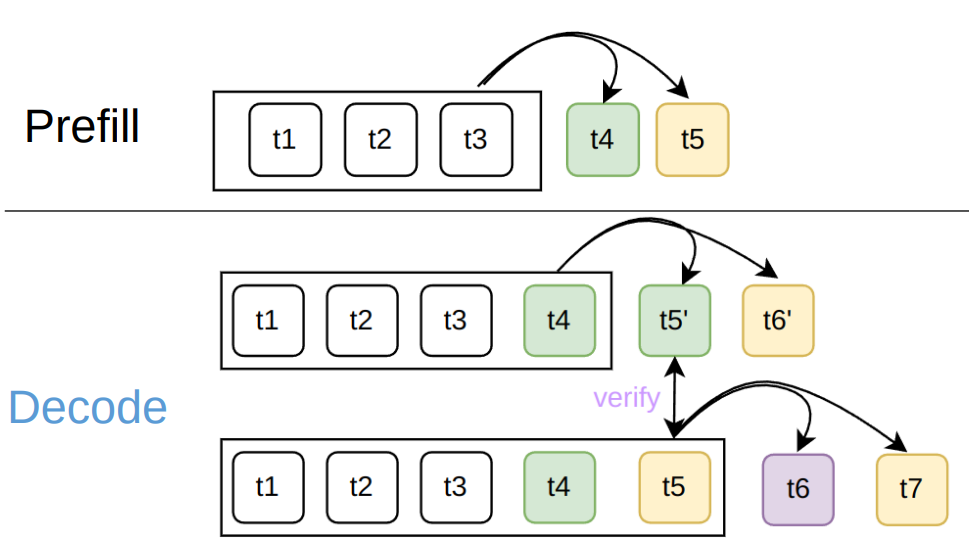
During the decode phase, both sequences utilize KV cache for tokens t1, t2, t3, t4. The first sequence uses the first three caches, while the second sequence uses all four caches.
When using standard attention operators, each sequence is computed independently, causing the same KV cache to be loaded repeatedly, resulting in significant waste. To eliminate this inefficiency and fully leverage the performance advantages of our MTP approach, we developed a custom MTP operator based on Flash Attention v3: fa3_mtp, and you can use it in lightllm’s fa3_mtp branch.
In the FA3 operator, during decode phase inference of DeepSeek-V3/R1 models, both kBlockM and kBlockN are set to 64. This means that during $QK^T$ matrix multiplication, kBlockM rows of the $Q$ matrix are multiplied with kBlockN rows of the transposed $K$ matrix. In MLA (Multi-head Latent Attention), since the number of $K$ heads is 1, kBlockN corresponds to kBlockN tokens. For kBlockM, under TP8 (tensor parallelism of 8) configuration, with 128 heads distributed as 16 heads per device, the $Q$ matrix only has 16 rows - far below the kBlockM requirement of 64. This creates significant resource underutilization. Recognizing this inefficiency, we integrated our MTP inference approach to develop the fa3_mtp operator.
This operator combines the queries (Q) of a group of sequences into a unified computation. During the $QK^T$ computation (where $Q$ is the query matrix and $K^T$ is the transpose of the key matrix), it dynamically sets the mask for the $Score$ matrix by calculating the seq_len corresponding to each q row. Through this approach, we can expand the effective $Q$ head count from the original 16 to 32, 48, or even 64, dramatically improving hardware utilization efficiency.
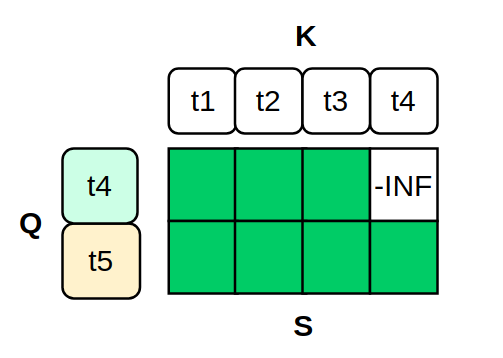
This is an example with mtp_step=1. In the operator, masking is applied based on the sequence length corresponding to $t4$, setting the $Score$ matrix values to -INF.
Based on the above principles, theoretically in our MTP mode, the fa3_mtp operator can achieve $(mtp\_step + 1) \times$ speedup compared to the standard fa3 operator when $qhead \cdot (mtp\_step + 1) \leq 64$. Our actual benchmark results confirm this theoretical prediction.
Benchmark
Performance evaluation of the fa3_mtp operator:
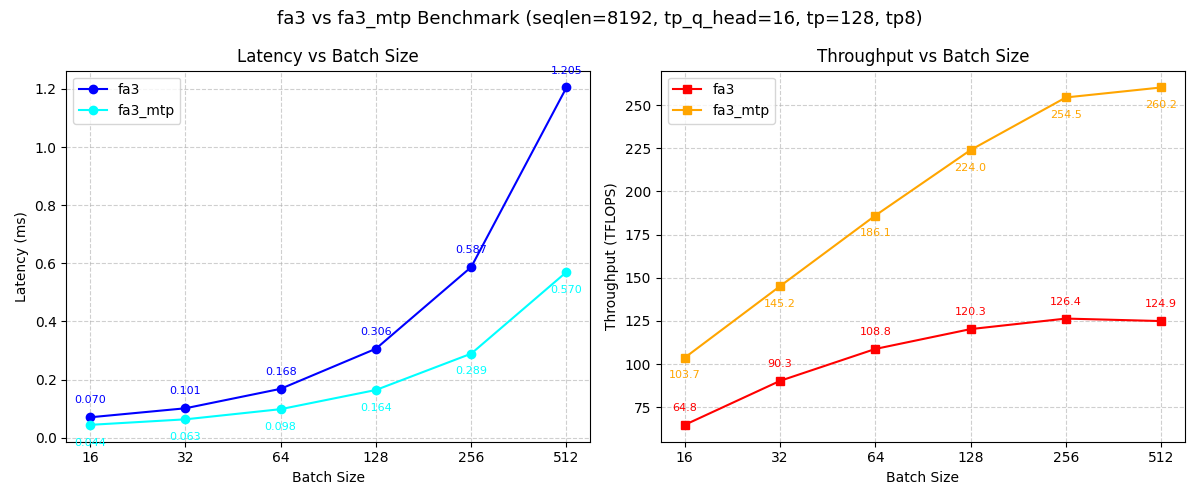
Comprehensive performance comparison between FA3 and FA3_MTP operators (seqlen=8192, tp_q_head=16, tp=128). Left: Latency vs Batch Size showing FA3_MTP achieves consistently lower latency. Right: Throughput vs Batch Size demonstrating FA3_MTP delivers significantly higher throughput, with improvements becoming more substantial at larger batch sizes.
Performance evaluation during the decode phase:
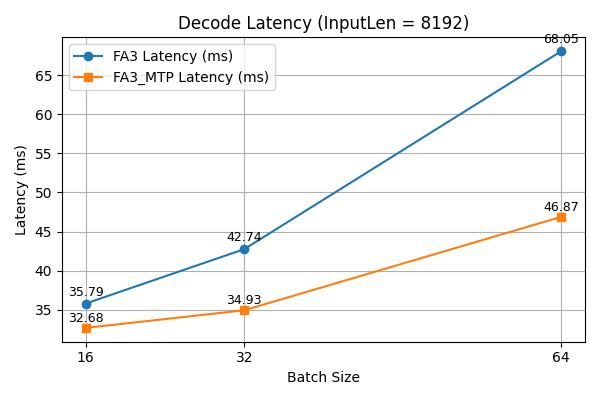
Latency comparison between standard FA3 and FA3_MTP operators across different batch sizes (InputLen = 8192). FA3_MTP consistently achieves lower latency, with performance advantages becoming more pronounced at larger batch sizes.